September, 2024
A Lifetime Under the Hood - From 6502 Machine Language to Fabric Parquet Files
 Mark Clancy
Mark Clancy
September, 2024
Mark Clancy
One of the most life-altering events in my life was receiving an Apple II+ as a gift when I was a teenager. That gift very likely led me into my current career path of being a data engineer.
The timing of the gift, 1981, was pre-web so there were very limited ways to learn more about computing --- books, magazines, word-of-mouth. For this reason, I often hung out at the local computer store looking for information. One of the first books I purchased focused on 6502 Machine Language. My interest in this was partly curiosity but, more likely, a desire to speed up games that I had written in the BASIC language. Given my lack of knowledge, I didn’t realize that a higher-level “assembly” language existed. My punishment for this lack of knowledge was having to write out on paper the individual hex codes that I needed and then to enter those into the computer.
So what does this story have to do with the open standard “Apache Parquet” file format used as the basis for many analytics platforms, including Microsoft Fabric? Well, I think it’s important for software / data engineers to balance the level of abstraction in which they’re working with some level of intuition as to how something works. In other words, you absolutely want to work with higher levels of abstraction and utilize lower-level libraries to boost your productivity. However, sometimes looking “under the hood” provides invaluable intuition as to how things work. I was recently struggling to understand how Parquet files worked by simply looking at specification documentation so I decided to take a deeper dive.
The first thing I did was to try to conceive the simplest Parquet file I could imagine. This is illustrated as the .CSV file (59 bytes) below:

Next, I uploaded the file to a Microsoft Fabric Lakehouse and then exported the resulting Parquet file. The result? A 2kB file. Now, I knew the file would be a binary file that wouldn’t easily reveal its contents. For fun, I did take a quick peek using a hex/ascii editor and I could see a few things of interest:
Given that we no longer live in a pre-web era, I was able to quickly move beyond looking at hex codes and began to really gain some insights into the format using both the specification from Apache and a tool called parquet-tools.
The Apache standard for Parquet outlines the format as follows:

This structure was consistent with what I had glimpsed in the hex editor. As expected, data is grouped by “column”, not by “row” and the data is followed by the metadata. This grouping approach is what underlies “columnar” databases and is ideal for analytics operations where your focus is often on filtering and aggregation. The documentation review was interesting but a bit high-level to really build intuition as to how the file is actually structured.
> parquet-tools inspect –detail filename.parquet
The rather long and colourful output below reveals the metadata for one of the column “chunks”:
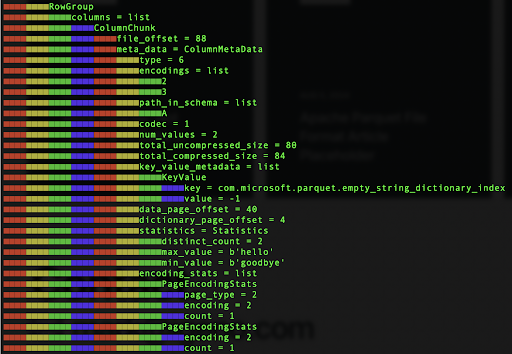
The metadata contains information such as column names, data types, min/max values of a column, number of values in the column and “offset” values which relate to where the data is positioned in the file.
We can take this knowledge of the Parquet file format and use it to inform our querying of parquet files. I have been using the SQL endpoint for Microsoft Fabric lately and these are some insights that I’ve found useful:
From my perspective, you want to spend the majority of your time at the highest level of coding possible, but peeking under the hood occasionally satisfies your curiosity and sharpens your intuition, especially when you’re learning new technologies. Steve Jobs expressed this eloquently when he said:
-- Steve Jobs
Mark Clancy is a senior data engineer based in Vancouver, Canada.
All author posts
